第 6 课:学习与生活场景——费曼与跨模态
🎯 核心实操目标
学习目标:掌握利用大模型把“学术难点”讲简单的概念化简方法。本节课后,你需要学会使用【费曼提示词】引导 AI 用通俗的白话文给你解释复杂的计量经济学或医学公式;同时使用 “跨模态视觉能力”,直接上传图表让 AI 看图说话。
📋 课前准备(5 分钟自检)
账号
- [ ] 豆包(必备,国内零基础友好):doubao.com
- [ ] 至少一个海外平台账号(任选其一):GPT-5 / Claude 4.8 / Gemini 2.5
工具/环境
- [ ] 一台可上网的电脑(Windows / Mac / Linux 均可)
- [ ] 任意浏览器(推荐 Chrome / Edge / Safari 最新版)
- [ ] 一份用于记录提示词与对话的本地笔记(Markdown / Word / Notion)
数据/素材
- [ ] 一段你自己工作/学习中真实卡住的文字问题(用作实操对象)
应急通道
- 海外平台无法访问 → 用国产替代:Kimi K2 / DeepSeek V3 / 通义千问
- 浏览器卡顿 → 关闭其他标签后重试,AI 网页对内存敏感
- 不会注册 → 加入课程答疑群索取注册教程
场景导入:看不懂的参数与复杂图表
在跨专业做综述,或是阅读顶刊 Nature/Science 时,常会遇到“异方差检验”“马尔可夫链蒙特卡洛模拟”这类陌生的专业名词,即便去查百科,得到的往往也是一堆难以理解的数学公式。 更常见的困扰是,文章里那些线条密集的“小提琴图”“多重共线性森林图”,反复研读也不容易看清作者到底想证明什么。
大模型的两项重要能力,一是把复杂概念讲简单的表达能力,二是视觉能力(多模态图像理解)。本节课,我们就用这两项能力来降低阅读学术内容的门槛。
处理流程:概念化简与读图
这是一条化繁为简的处理流程,我们从两条路径入手:对正文使用“费曼比喻法”,对图片使用“视觉信息提取”。
📖 本节关键术语(先认词,再上手)
- 费曼技巧(Feynman technique):以理查德·费曼命名的学习方法,核心是“假装把一个概念讲给完全外行的人听”——若讲不通,说明你自己没真懂。本节把它改造成一种提示词策略:要求 AI 用零公式、贴近生活的比喻,把学术概念重述到“能转述给长辈”的程度。
- 多模态 / 跨模态(multimodal / cross-modal):指模型能同时处理多种信息形态(文本、图像等)。“跨模态”在本节特指“上传一张图、用文字提问,模型据图作答”这种图文混合的用法。具备此能力的模型常被称作视觉语言模型(Vision LLM)。
- 类比 / 喻体(analogy / vehicle):用一个已熟悉的事物(喻体,如“菜市场买肉”)去说明一个陌生概念(本体,如“流动性陷阱”)。本节反复强调的“一喻到底”,就是指全段只用一个喻体。
- 幻觉(hallucination):模型生成了流畅但与事实不符的内容。读图时尤其要警惕——模型可能“看”出图上并不存在的趋势。
- 负向提示(negative prompting):用“不要……”明确划出禁区(如“不要出现任何公式”)。本节大量依赖它来约束输出,详见第 2 课。
🧠 为什么费曼比喻法有效,又为什么会失真(原理)
理解下面两点,你就不会把这套方法用过头。
为什么生活化类比能讲清概念。 大模型本质上是在按训练语料中的统计规律预测下一个最可能的词,而不是去查询某个权威事实库。日常生活场景(菜市场、抬扁担)在训练语料里出现频次极高、语言极其通顺,因此模型用这类场景作答时,往往能产出流畅、连贯、贴近直觉的表达。对读者一侧,作用机理可理解为“用已知映射未知”:把陌生概念挂靠到你早已熟悉的生活经验上,能显著降低理解所需的认知负荷——你不必同时消化新概念和一堆新符号,只需把熟悉画面里的关系迁移过来。这就是为什么“零公式 + 贴近生活”往往比“严谨定义”更好懂。
为什么‘单一喻体贯穿’很重要。 每换一个喻体,读者就得在脑子里重建一套全新的对应关系,前面建立的画面随之作废,认知负荷不降反升。坚持“一喻到底”,则同一套熟悉关系能反复复用,理解才会累积。这也解释了为什么本节反复用负向提示写死“中途不要换比喻”。
为什么会失真。 类比的本质是“部分相似”,绝不是“完全等同”。喻体只在某些侧面贴合本体,越过那些侧面就会失真——例如用“菜市场的货会过期”去类比“现金”,但现金并不会过期,这一处对应就是错的。更要紧的是:模型按语言流畅度生成比喻,它倾向于把话说圆,却没有接入可信事实库来逐一校验“这个生活细节到底对不对得上真机理”。因此越是顺口、越是漂亮的比喻,越要回到严谨定义去验一遍对应关系——这正是下面“边界与局限”要展开的。
🚀 实操 A:费曼概念化简(文本领域)
📋 示例场景:你拿到了一批货币经济学文献,而你是一名文科背景的读者。文章里反复讨论“量化宽松下通过拉姆齐模型导致的热钱涌入与流动性陷阱”。这时可以直接使用下面的化简提示词。
【Role】你是一位擅长把枯燥知识转化为通俗段子的跨界科学家。
【Objective】
我是一个平时连基础方程函数都看不懂、只熟悉菜市场和超市的零基础文科生。
我现在需要搞懂这几个比较陌生的名词:“流动性陷阱”、“拉姆齐模型中的跨期消费”。
请你尽量不要使用任何一行包含 x、 y 或者微积分的公式。
请基于“在菜市场买猪肉和萝卜”这样贴近生活的场景,为我生动地演绎并比喻出这两个理论的本质核心。越通俗越好,要让我听一次就能转头讲给家里的长辈听。回车之后,那些抽象的学术公式就会被翻译成“你手里拿着一百块钱,猪肉涨价时你选择把钱存起来而不买肉”这样直观的画面。这就是概念化简。
对照样例:一段合格的费曼输出长什么样
光说“会变生动”不够,你还要能认出什么是真正合格的化简、什么只是换了一套术语。下面用同一个名词“流动性陷阱”给出两个对照。
✅ 合格输出(菜市场比喻,零公式,可转述给长辈)
你拿着一百块钱去菜市场,本来想买猪肉。可你发现今天猪肉、萝卜、鸡蛋统统在降价,而且摊主说明天可能更便宜。于是你攥着这一百块谁也不买,就等着再跌——结果全市场的人都跟你一样攥着钱不花。摊主东西卖不动,只好继续降价,大家就更舍不得花,钱像被一个看不见的坑“陷”住了,怎么催都流不出来。这个“无论多便宜大家都把钱攥死、市场转不动”的死循环,就是经济学说的“流动性陷阱”——不是没钱,是钱都趴着不动了。
为什么合格:全程没有一个 x/y/利率符号;“攥着一百块不花”这一个生活动作从头贯穿到尾;最后一句把术语翻译回大白话,长辈听完能复述。
❌ 失败样例(看似在解释,实则换了一批术语,仍然难懂)
流动性陷阱指名义利率触及零下界(ZLB)后,货币需求对利率的弹性趋于无穷大,央行即便扩张基础货币、提升 M2 增速,也无法进一步压低实际利率以刺激投资与消费,从而使 IS-LM 框架下的货币政策传导机制失效。
为什么失败:通篇是“零下界”“弹性”“IS-LM”“传导机制”——它只是把一个术语换成了五个新术语,并没有真正化简。一个文科零基础读者读完依然不知道这到底在讲什么,更别说转述给长辈。这正是需要留意的一种情况:AI 看似在“解释”,实际并没有把概念讲简单。
怎么判断 AI 给的是不是“真正的化简”——三条可核对判据
不必被“图像解析”“概念化简”这类说法绕住。把判据归纳成三条,你当场就能核对 AI 的输出合不合格:
| 判据 | 通过标准 | 上面失败样例为何不通过 |
|---|---|---|
| 零公式 | 全文没有任何 x、y、利率符号、希腊字母或微积分 | 出现了 ZLB、M2、IS-LM 等符号化术语 |
| 一个生活动作贯穿 | 有一个具体生活动作(如“攥着钱不买肉”)从头讲到尾 | 没有任何生活画面,全是抽象名词堆叠 |
| 能转述给长辈 | 你读完能用大白话复述给家里不懂经济学的长辈听 | 长辈(甚至你自己)听完仍不知所云 |
一句话记法:好的化简 = 零公式 + 一个生活动作贯穿 + 能转述给长辈。三条但凡缺一条,就让 AI 重讲,不要将就。
逐要素拆解:同一个比喻,写好与写砸只差这几下
上面是整段的对照。但学员真正容易踩坑的不是“整段写砸”,而是一段里某几句没控制住——前半段比喻得好好的,后半段突然换了喻体或夹进公式,整段就废了。下面把“写好 vs 写砸”拆到要素一级,每一行都是一个你下笔时要守住的具体动作。
| 写作动作 | ❌ 写砸的写法 | ✅ 写好的写法 |
|---|---|---|
| 选喻体 | 一会儿用“菜市场买肉”,一会儿又跳到“开车踩刹车”“水库蓄水”——三个喻体混在一段里 | 全段只认准一个喻体(菜市场买肉),从开头讲到结尾绝不换 |
| 接公式 | “也就是说货币需求弹性 → ∞,于是 ΔM 无法压低 r”——比喻讲一半又把公式塞回来 | 公式一个不出现;要表达“利率压不下去”就说“东西再便宜大家也不掏钱” |
| 保术语 | 比喻里夹一句“这其实就是 IS-LM 传导失效” | 术语只在最后一句点一下名(“这就叫流动性陷阱”),正文全是大白话 |
| 对应关系 | 喻体和原理对不上:“钱像猪肉一样会过期”——可现金并不会“过期”,比喻失真 | 每个生活细节都对应一个真实机理:“攥钱等更便宜”对应“预期通缩→延迟消费” |
| 收尾翻译 | 戛然而止,没把比喻翻回术语,读者不知道刚才讲的是哪个名词 | 结尾一句把比喻翻译回术语原名,读者能把画面和名词挂上钩 |
记忆口诀:一喻到底、零公式、术语只在收尾点名、每个细节都对得上真机理。这四条任意一条破了,就是上面 ❌ 那一列的情形。
🔬 跨学科 worked example:用费曼讲清「多重共线性」(经管面板数据)
前面的例子来自货币经济学(偏文科读者)。这里换一个理工/经管学员高频遇到、且偏统计的难点——多元回归里的“多重共线性(multicollinearity)”,看费曼法如何迁移。
📋 示例场景:你在用 Case B 的省级面板数据(case_B_provincial.csv,30 省 × 10 年)跑回归,因变量是 Innovation_Index,你同时放入了 DigEcon_Index(数字经济指数)和 HumanCap_per10k(每万人专科以上学历人数)两个自变量。导师说“你这俩自变量怕是有多重共线性”,但你不懂这五个字到底在说什么、为什么是个问题。
【Role】你是一位擅长把统计学概念翻成生活白话的跨界讲师。
【Objective】
我是一个只会跑回归、但完全不懂背后原理的零基础学员。
我需要搞懂一个名词:“多重共线性(multicollinearity)”。
背景:我在做一个省级面板回归,因变量是“地区创新指数”,我同时放了两个自变量——
“数字经济指数”和“每万人高学历人数”,导师说这两个自变量之间可能有多重共线性。
要求:
1. 全程不要出现任何公式、相关系数、VIF、矩阵这类符号或术语;
2. 只用“两个人合伙抬同一根扁担送货”这一个生活场景,从头比喻到尾,中途不要换别的比喻;
3. 讲清三件事:(a) 多重共线性到底是什么;(b) 它为什么会让回归结果不可靠;(c) 一般怎么应对;
4. 最后一句话,把这个生活场景翻译回“多重共线性”这个术语本名。预期输出(合格示范):
你雇了两个人帮你抬一根扁担送货,一头挑着货物,你想知道这趟货到底是谁出的力多、谁该多拿工钱。可这两个人身高、步子、力气几乎一模一样,永远肩并肩一起走、一起使劲——你站在旁边怎么看都分不清这根扁担到底是左边那位扛起来的,还是右边那位扛起来的。你今天说“主要靠左边”,明天换个角度看又觉得“好像是右边”,给的工钱忽高忽低,没法定。
回到你的回归:“数字经济指数”和“每万人高学历人数”就是这两个步调一致的人。它俩本身高度同涨同落,模型也分不清“创新指数”这趟货到底是哪个自变量扛起来的,于是给它俩估出来的“功劳”(系数)会忽大忽小、甚至正负翻转,你换一批样本结论就变——这就是为什么结果不可靠。
应对也顺着这个比喻:要么干脆只留一个人去抬(删掉其中一个高度重复的自变量),要么把两个人合并成一个“小组”整体算工钱(把两个变量合成一个指标),要么再多请几个步调不同的人来对比(增大样本或引入差异化变量)。
这个“两个人步调太一致、分不清各自功劳”的情况,统计学里就叫“多重共线性”。
为什么这段合格:它守住了上面那张表的全部四条——一喻到底(自始至终是“两人抬扁担”,没跳到别的场景)、零公式(没有相关系数、没有 VIF、没有矩阵)、术语只在收尾点名、且每个生活细节都对得上真机理(“分不清谁出力”对应系数不可识别、“工钱忽高忽低”对应系数不稳定、“只留一个人/合并/多请人”对应删变量/降维/扩样本三种真实做法)。这正是费曼法从“文科货币经济学”迁移到“经管统计概念”的样子。
🚀 实操 B:视觉看图说话(多模态图解)
📋 示例场景:你截图了一份复杂的折线图(参考下方示例,可以右键保存该图用于练习),图上有十几条不同颜色的折线交织在一起,你需要从中提取核心信息。
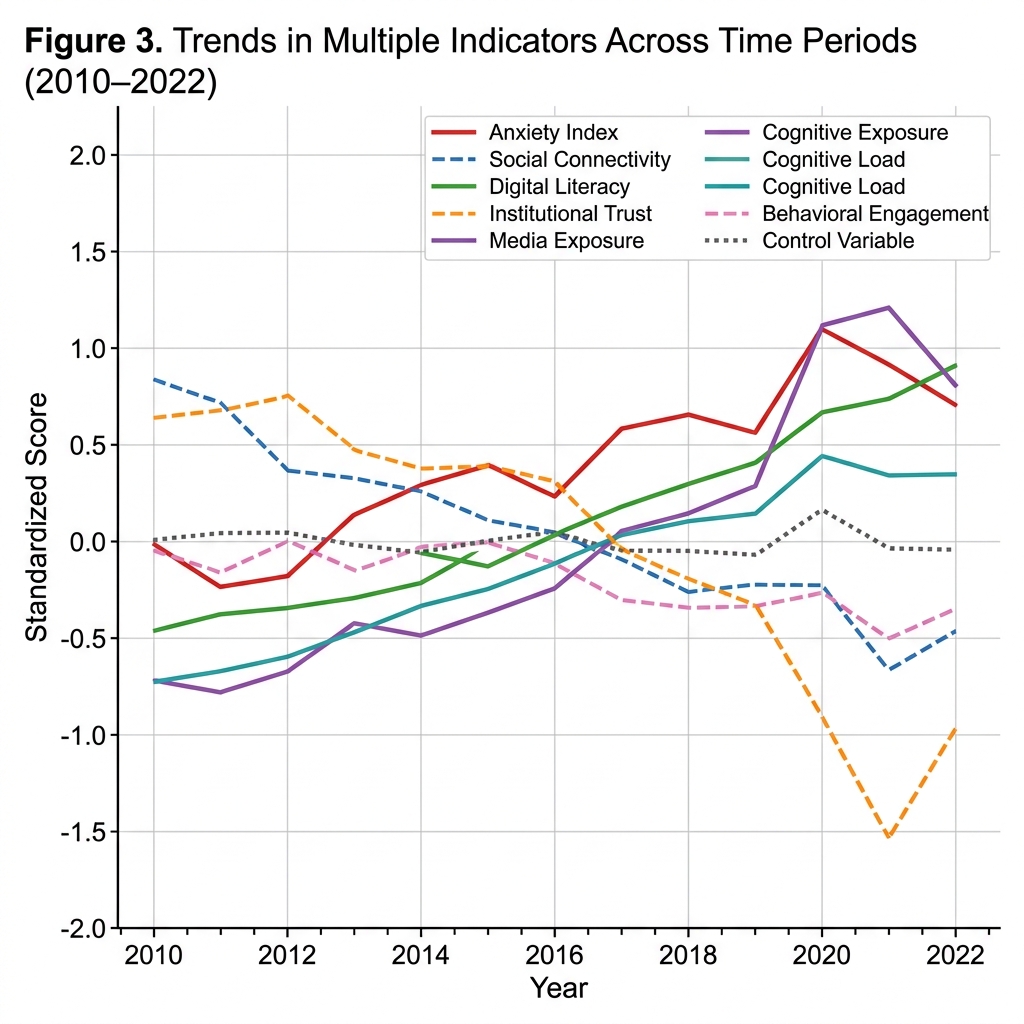
操作步骤:启用多模态视觉能力
请选择具备看图能力的主流大模型(如 GPT-5 或 Google Gemini 2.5 Pro),直接将复杂图表截图并粘贴进输入框(按 Ctrl+V)。
【角色设定】我们正坐在这篇论文的答辩现场。你是一位观察细致、对异常数据较为敏感的资深审稿专家。
【目标】
请对上方这张较为复杂的交叠趋势图进行关键数据的逐层提取。我不需要你做流水账式的描述。
请直接回答以下三个关键问题:
1. 图中有哪几条颜色或标注的线,在最近的五年区间内,偏离了常规周期、出现了反常的【逆势增长或大幅回落】?
2. 试推断这张图想要证明的最核心的一个论点是什么?
3. 从数据的留白处看,该图作者可能未能呈现或未能收集到哪个维度的关联数据?💡 【读图是线索,不是结论——必须回原数据核验】
模型能帮你提取候选观察点,例如它可能提示"2015 年后的波动看起来更密集,值得你去核对"。但这类仅凭一张图素得出的推断是"待验证假设",不是结论——AI 完全可能把坐标轴间距、视觉错觉看错。 正确用法:把 AI 指出的可疑点回到原始数据/原表逐一核对(这一年到底是不是真的更高?样本量够吗?),再决定是否写进论文。这正是下一课(第 7 课四维质检)要训练的"AI 读图 → 人工复核"习惯。绝不能把 AI 的读图推断直接当成你的研究发现。
对照样例:同一张折线图,合格回答 vs 流水账回答
假设你上传的是 Case B 的一张折线图:横轴 Year(2014–2023),纵轴 DigEcon_Index(数字经济发展指数,范围 20–95),三条线分别是 Region 的 East / Central / West 三大地区。下面给你同一张图的两种回答,你要学会一眼分辨哪种能写进论文。
❌ 流水账回答(不合格:把数字念了一遍,没有发现)
这张图有三条线。East 线从 2014 年的约 78 一路升到 2023 年的约 87;Central 线从约 55 升到约 68;West 线从约 48 升到约 59。三条线都在上升,East 一直最高,West 一直最低,Central 居中。三条线在十年里都没有交叉。
为什么不合格:它只是把每条线的起点终点逐个念了一遍,结论是“都在涨、East 最高”——这些一眼就能看出来,等于没分析。它没有指出哪条线、哪个区间出现了反常,对写论文没有增量价值。
✅ 合格回答(指明具体哪条线、哪个区间反常)
值得回到原表核对的是 West 线在 2020–2022 这个区间:其余两条线(East、Central)在这三年仍保持原有的平缓上行斜率,唯独 West 的
DigEcon_Index出现了一段明显陡升,斜率约为它自己 2014–2019 年均速的两倍,使它与 Central 的差距从约 13 个点收窄到约 9 个点。这是全图唯一打破“三线平行上行”常规节奏的地方。核心论点很可能是:数字经济在欠发达地区(West)存在“后发追赶”的加速窗口。提醒:以上是读图得到的待验证假设,West 这段陡升必须回
case_B_provincial.csv按Region == 'West'逐年核对DigEcon_Index真值,确认不是坐标轴视觉错觉后才能写进论文。
为什么合格:它精确锁定了唯一一条线(West)+ 一个具体区间(2020–2022)+ 一个可量化的反常(斜率约为自身前期两倍、与 Central 差距由 13 收窄到 9),并据此给出一个单一论点;同时主动声明这是待核验假设,与上方警告完全一致。
⚠️ 常见误区与纠正
本节两项技能(费曼化简、看图说话)学员最常踩的坑集中在下面五条。对照自查,犯了哪条就按右列纠正后重发。
| 常见误区 | 后果 | 纠正方法 |
|---|---|---|
| 中途换喻体:前半段“菜市场买肉”,后半段又跳到“开车踩刹车” | 读者刚建立的画面被打断,整段反而更乱 | 在提示词里写死“只用 XX 这一个场景从头比喻到尾,中途不要换别的比喻” |
| 比喻里夹公式/符号:讲一半塞回 ΔM、VIF、利率符号 | 等于没化简,文科/零基础读者照样卡住 | 提示词明确“全程不出现任何公式、希腊字母、专业符号”;输出里一旦出现就让它重写那一句 |
| 比喻失真:生活细节和真机理对不上(如“现金会像猪肉一样过期”) | 学员被错误直觉误导,比不解释还糟 | 自查“每个生活细节是否都对应一个真实机理”,对不上的细节删掉或换 |
| 术语全程不点名:通篇大白话,但从没说清讲的是哪个名词 | 学员听懂了画面,却不知道对应教材里哪个术语,无法迁移 | 要求“结尾一句把比喻翻译回术语本名” |
| 读图当结论:把 AI 从一张图里读出的推断直接写进论文 | 坐标轴错觉、样本不足等都可能让推断是错的 | 一律视为“待验证假设”,回原始数据/原表逐点核对后再采信(见上方 ⚠️ 警告与第 7 课四维质检) |
🔁 输出仍不满意?这样迭代
首版输出不理想是常态,不要重开一个对话从头再问,而是在同一条对话里做定向纠偏——这正是第 2 课讲过的“负向纠偏 / 迭代修正”手法在本节的具体落地:
- 化简还是太难 → “刚才那段里‘弹性’‘传导机制’这些词我还是不懂,请把它们也用菜市场场景讲,并且这一版一个公式符号都不要。”(点名要删的具体词,比泛泛说“再简单点”有效得多)
- 比喻换来换去 → “你这版从买肉跳到了开车,请只保留买肉这一个比喻重写,开车那段删掉。”
- 读图太流水账 → “不要逐条念数字,请只告诉我哪一条线、哪个区间偏离了常规,并给一个量化幅度。”
- 方向带偏了 → 用第 2 课的负向约束兜底:“不要给我教科书定义,不要展开历史背景,只要那个生活比喻本身。”
一句话:把不满意的地方指名道姓地说出来,让 AI 在原文上改,而不是寄希望于换个问法重抽一次。
🗺️ 把方法用成体系:何时用费曼、何时用读图、用哪种比喻
前面给的是两条具体路径,但实操中你需要的是一张“遇到什么困难、走哪条路”的判断图,而不是死记两个提示词。把本节方法归纳成下面的体系。
第一层:先分清是“看不懂的文字”还是“看不清的图”。
| 你卡住的对象 | 走哪条路径 | 本节对应实操 |
|---|---|---|
| 一段文字/公式/术语(如“流动性陷阱”“多重共线性”) | 费曼概念化简(文本) | 实操 A |
| 一张图表/示意图/外文框图(折线、小提琴图、森林图) | 跨模态读图(视觉) | 实操 B |
| 既有难懂文字、又配着难懂图 | 先读图提取候选观察点,再用费曼把机理讲透——两条路径串联 | A + B |
第二层:选喻体也分情形,不是只有“菜市场”一种。 费曼法的喻体要按概念的底层结构来挑,挑对了才不容易失真:
| 概念的底层结构 | 适配的喻体类型 | 本节/课程中的例子 |
|---|---|---|
| 关于选择与预期(钱该不该花、何时消费) | 日常交易/买卖场景 | 流动性陷阱 → 菜市场攥钱不买肉 |
| 关于两个量纠缠、分不清各自贡献 | 两人协作/合力场景 | 多重共线性 → 两人抬同一根扁担 |
| 关于流量、积累与阈值(蓄水、溢出) | 容器/水流场景 | 适用于“存量 vs 流量”“饱和效应”类概念 |
| 关于信号在中间环节被削弱/放大 | 传话/中介(mediator)场景 | 适用于中介效应、政策传导类概念 |
挑喻体的准则只有一条:喻体的内部关系,要和概念的真实机理同构。结构对上了,“一喻到底”才讲得下去;硬套一个结构不对的喻体,必然中途换喻或失真。
第三层:读图也分‘问什么’。 同一张图,问法不同,价值天差地别:
- 找异常(哪条线、哪个区间偏离常规)——本节主推,信息增量最高;
- 提论点(这张图想证明的单一核心结论)——适合快速把握作者意图;
- 挑留白(作者可能漏报/未收集的维度)——适合做综述时找研究缺口。
实操 B 的提示词正是把这三问打包在一起。边界条件:以上都只产出“待验证假设”,不产出结论——原因见下一节。
🚧 边界与局限:这两项能力在什么情况下会失效
诚实地标出边界,比多给一个例子更重要。本节两项能力都不是“万能翻译器”,下面是它们确凿会出问题的地方。
费曼化简的边界——类比天生会失真,越界处必须回到严谨定义。
- 类比只是“部分相似”:喻体贴合概念的某几个侧面,超出这些侧面就会误导。“菜市场攥钱不买肉”能讲清“预期通缩→延迟消费”,但它讲不了利率传导的精确机制;硬要用它推导“央行该降息多少”,就越界失真了。判断越界的信号:当你需要的是精确数值、严格条件、可推导的结论时,类比就到头了,必须切回教材里的严谨定义和公式。
- 化简不能替代理解:能把概念“听懂个大意”不等于“会用它做研究”。比喻帮你跨过入门门槛,但写进论文、做计算、下判断时,依据必须是严谨定义,不能是“老师那个买肉的比喻”。
- 越简单越可能丢精度:要求“越通俗越好”会让模型为了顺口而省略限定条件(如“在短期、在零利率附近”)。这些被省掉的前提,往往正是学术严谨性所在。
跨模态读图的边界——模型“看错”的方式很具体。
- 会把视觉错觉当数据:坐标轴是否等距、是否截断(不从 0 开始)、对数还是线性,模型都可能误判,从而把“看起来陡”错当成“真的陡”。
- 会读出图上没有的趋势(幻觉):线条密集、颜色相近时,模型可能“脑补”出一条并不存在的关系,且语气照样自信。
- 精读细节不可靠:具体数值、第几年的拐点、两线交叉的确切位置,读图常有偏差,不能直接引用。
- 唯一安全的用法:把读图结果一律当成待验证假设,回到原始数据(如
case_B_provincial.csv)逐点核对后才采信。这与上文 ⚠️ 警告、第 7 课“四维质检”是同一条红线。
共同的准确性与伦理红线。
- AI 的解释和读图都可能错且不自报错——它没有接入可信事实库来校验自己,输出的自信程度与正确程度并不挂钩。
- 凡要写进论文的,都要回到原始材料核验:费曼比喻里的机理对应、读图得到的趋势,都属于“线索”,核验通过才算“证据”。
- 保留人工判断的主体地位:方法是降低门槛的脚手架,研究结论的责任始终在你,不能转嫁给模型。
📦 本课交付物
按本节实操任务完成并提交以下内容,提交 AI 初审,按 Module_Rubrics.md 对应维度评分:
- [ ] 本节实操产出:本节任务区块要求的具体文件 / 文本 / 截图
- [ ] AI 协作日志:至少 1 段完整的"任务描述 → AI 输出 → 人工修正"对话记录
- [ ] 四维质检记录:用
Course_QA_Checklists.md(事实/逻辑/格式/引用)核查本节 AI 输出的笔记 - [ ] 沉淀模板:将本课关键 Prompt / 流程 / 检查清单加入你的个人工具箱
📝 本章小结
本节解决一个具体问题:当学术内容(文字或图表)的门槛太高时,如何借助大模型把它降到能理解的高度,同时不让“好懂”牺牲“可靠”。把全章凝练成可复习的要点:
- 两条路径,按对象选。 看不懂的是文字/公式就走费曼概念化简(实操 A);看不清的是图表就走跨模态读图(实操 B);两者皆有则先读图找候选、再用费曼讲透机理。
- 合格的费曼化简 = 零公式 + 一个生活动作贯穿 + 能转述给长辈。 三条判据当场可核对,缺一条就让 AI 重讲。落到要素一级,要守住“一喻到底、零公式、术语只在收尾点名、每个细节都对得上真机理”。
- 原理上,生活化类比之所以好懂,是因为它“用已知映射未知”、降低认知负荷;“一喻到底”之所以重要,是因为换喻体会迫使读者重建对应关系。但类比是部分相似,本质会失真。
- 喻体要按概念的底层结构挑(交易类→买卖场景、纠缠类→合力场景、流量类→水流场景、传导类→中介场景),结构同构才讲得下去。
- 合格的读图 = 锁定具体哪条线 + 哪个区间 + 一个可量化的反常,而不是把数字念一遍;问法可在“找异常 / 提论点 / 挑留白”三者间选。
- 红线:费曼比喻在需要精确数值或严格条件处会越界,越界就回到严谨定义;读图可能把视觉错觉、甚至不存在的趋势(幻觉)当真。两者的产出都只是待验证假设,必须回原始数据核验后才能写进论文——这正衔接第 7 课的四维质检。
- 迭代靠指名道姓:不满意时在同一对话里点名要删的词、要留的比喻,而不是换个问法重抽(呼应第 2 课的负向纠偏)。
✅ 自测清单
- [ ] 我已经掌握了利用“费曼比喻法”进行概念化简的方法,并能用三条判据核对输出是否合格。
- [ ] 我明确了当被复杂图表或生僻外文框图难住时,可以将截图通过多模态交给 AI 解析。
- [ ] 我懂得在解析数据图表时,要引导大模型去寻找“异常变化点”,而不仅仅是“把图里的数字念一遍”。
- [ ] 我能说出费曼类比为什么有效、为什么会失真,并知道在需要精确结论处要切回严谨定义。
- [ ] 我清楚费曼输出和 AI 读图都只是“待验证假设”,写进论文前必须回原始数据核验。
🤔 思考与练习
下面 3 道题用于应用本节概念,区别于课程交付物。每题附“好答案的判断要点”,便于自查。
练习 1(费曼迁移到心理测量)。 Case A 的心理问卷(N=500)里有一列 Anxiety_4_R,列名末尾的 _R 表示这是一道反向计分题(reverse-scored item)。请写一段费曼提示词,要求 AI 只用一个生活场景、零公式地讲清“为什么有的题目要反向计分、不反向计分会出什么问题”,并在结尾把比喻翻译回“反向计分”这个术语本名。
好答案的判断要点:提示词里写死了“一喻到底 + 零公式 + 收尾点名术语”三项约束;选的喻体结构要和“同一态度、正反两种问法”同构(例如“同一件事,有人问‘你满意吗’、有人问‘你不满意吗’,答案得对着翻一下才能合并统计”);能说清不反向计分会让“高分”在两类题里指向相反含义,从而污染总分。
练习 2(识别失真的边界)。 有学员用“水库蓄水、水满则溢”来比喻 Case B 里 HumanCap_per10k(每万人专科以上人数)对 Innovation_Index 的作用,声称“人才蓄到一定水位,创新就会溢出来”。请指出:这个比喻在哪个侧面贴合、哪个侧面会失真?到什么程度时必须放弃比喻、回到严谨表述?
好答案的判断要点:能区分“部分相似 vs 完全等同”——“蓄水有阈值/饱和效应”这一侧面或许贴合,但“水满必溢、溢出是坏事”等细节未必对应真实机理(人才增加未必有硬阈值,也未必导致负面“溢出”);能指出当需要判断系数显著性、给出精确弹性、下政策结论时,比喻已越界,必须回到回归结果与严谨定义。
练习 3(读图问法设计 + 守住红线)。 针对 Case C 的 LLM 评估数据(300×3,三名标注者对 Quality_GPT5/Quality_Claude47/Quality_Gemini25 的 1–5 分打分),假设你拿到一张“三个模型质量分布的箱线图”。请写出三个层次(找异常 / 提论点 / 挑留白)各一问,并写一句话说明拿到 AI 的读图回答后第一步要做什么。
好答案的判断要点:三问层次分明——找异常(如“哪个模型的箱体或离群点明显异于另两个”)、提论点(“这张图最想支持的单一结论是什么”)、挑留白(“图里没呈现的维度,例如标注者间一致性/评分者信度,是否正是缺口”);最后一句必须落到“把读图结论当待验证假设,回到原始 300×3 评分逐点核对(含标注者一致性)后再采信”,体现本节红线与第 7 课衔接。